01
Production LLM Deployment
Deploy reliable LLM workloads across private, hybrid, and dedicated GPU environments with monitoring, governance, and operational controls built in.
ProsGrow AI Labs builds infrastructure for fine-tuning, private deployment, inference optimization, and GPU-efficient LLM operations.



Built for Efficient LLM Inference at Scale
High-throughput serving pipelines for real-time and batch inference workloads, designed to improve latency, reliability, and cost efficiency.
Quantization, pruning, and compression workflows that reduce memory footprint and improve deployment efficiency without redesigning the application stack.
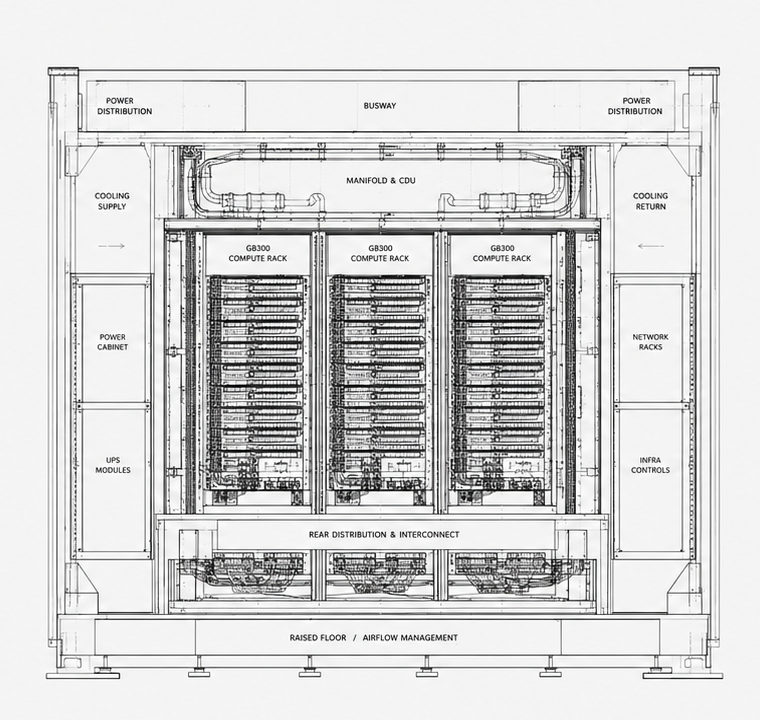
Route workloads across models, endpoints, and GPU pools based on latency, cost, availability, and workload priority.
Efficient fine-tuning and adaptation workflows for enterprise data, domain-specific tasks, and production deployment.
Platform
01
Deploy reliable LLM workloads across private, hybrid, and dedicated GPU environments with monitoring, governance, and operational controls built in.
02
Improve latency, throughput, GPU utilization, and cost per token through optimized serving, batching, routing, caching, and model compression.
03
Run inference workloads with usage tracking, autoscaling, observability, workload routing, and utilization optimization across GPU clusters.